
CodToys - EP04:請支援近義詞
上一章我們可以很快速地選擇目標顏文字了。
但是日子久了,一不小心就忘記當初顏文字的 tag 是甚麼,導致一時找不到想要的顏文字。( ´•̥̥̥ ω •̥̥̥` )
路人:「自己新增的 tag 還能忘記喔?(◉◞౪◟◉ )」
鱈魚:「我就鱈魚腦,你有意見膩?(;´༎ຶД༎ຶ`)」
你是個成熟的程式惹,該自己知道近義詞了!(。-`ω´-)
這樣即使忘記原本的 tag,也可以透過相近的字詞找到想要的顏文字了!ヾ(◍'౪`◍)ノ゙
開發
目前想到的實作方式為:「使用 LLM(Language Learning Model)來回答 tag 的中英文近義詞,再對近義詞進行模糊匹配」
本章節預計會建立以下內容:
- 在 Electron 中運行 LLM
- 讓 LLM 對每個顏文字的 tag 產生近義詞
- 根據近義詞搜尋並顯示結果
來運行 LLM 吧!
這裡依賴 node-llama-cpp 這個套件,藉由此套件我們可以很簡單的在 Node.js 中運行 LLM。
這裡選用小型的模型(大模型也跑不動就是了 (\´・ω・`)),目前實際測試 gemma-2-2b-it-Q6_K_L 和 Llama-3.2-3B-Instruct.Q6_K。
程式碼很單純,基本上就是微調官方範例而已。
讓模型回答特定單字的中英文近義詞,並將結果顯示出來。
import path from 'node:path'
import { fileURLToPath } from 'node:url'
import chalk from 'chalk'
import { getLlama, LlamaChatSession, resolveModelFile } from 'node-llama-cpp'
const __dirname = path.dirname(fileURLToPath(import.meta.url))
const modelsDirectory = path.join(__dirname, '..', 'models')
const llama = await getLlama()
const qList = [
'快樂的 10 個繁體中文、10 個英文近義詞,全部合併,逗號分隔,不要任何附加資訊,不要標題,不需解釋',
'慶祝的 10 個繁體中文、10 個英文近義詞,全部合併,逗號分隔,不要任何附加資訊,不要標題,不需解釋',
'發瘋的 10 個繁體中文、10 個英文近義詞,全部合併,逗號分隔,不要任何附加資訊,不要標題,不需解釋'
]
{
console.log(chalk.yellow('gemma: '))
const modelPath = await resolveModelFile(
'hf_bartowski_gemma-2-2b-it-Q6_K_L.gguf',
modelsDirectory
)
const model = await llama.loadModel({ modelPath })
const context = await model.createContext()
const session = new LlamaChatSession({
contextSequence: context.getSequence()
})
console.log()
for (const q of qList) {
const a = await session.prompt(q)
console.log(a)
}
await model.dispose()
}
{
console.log(chalk.yellow('llama: '))
const modelPath = await resolveModelFile(
'hf_mradermacher_Llama-3.2-3B-Instruct.Q6_K.gguf',
modelsDirectory
)
const model = await llama.loadModel({ modelPath })
const context = await model.createContext()
const session = new LlamaChatSession({
contextSequence: context.getSequence()
})
console.log()
for (const q of qList) {
const a = await session.prompt(q)
console.log(a)
}
await model.dispose()
}以下是運行結果。
gemma:
幸福、欣喜、愉悅、歡樂、開心、滿足、喜悅、興奮、滿足、舒暢
joy, happiness, delight, exhilaration, contentment, pleasure, satisfaction, excitement, bliss, comfort
慶祝、歡慶、慶典、盛會、派對、聚會、節慶、紀念、典禮、嘉年華
celebration, festivities, party, gathering, jubilee, festival, commemoration, gala, ceremony, parade, anniversary
發瘋、瘋狂、失控、歇斯底里、狂躁、衝動、失序、失常、暴躁、躁狂
madness, frenzy, unhinged, manic, agitated, impulsive, chaotic, disordered, irritable, erraticllama:
快樂、愉悅、幸福、欣快、高興、快意、悅目、愉悅、快樂、快暢
慶祝、祝賀、紀念、紀念、祝福、慶典、節日、節慶、紀念、祝賀
發瘋、癲癇、瘋狂、亢進、狂躁、癡呆、癲癇、瘋狂、亢進、狂躁可以看出 gemma 的回答品質比 llama 好很多,所以接下來讓我們採用 gemma 實現近義詞搜尋吧。( ´ ▽ ` )ノ
新增 LLM API
安裝 node-llama-cpp 之後,新增自動下載模型的 scripts。
package.json
{
"name": "cod-toys",
// ...
"scripts": {
"dev": "vite --host",
"build": "vue-tsc --noEmit --skipLibCheck && vite build",
"preview": "vite preview",
"test": "vitest",
"test:ui": "vitest --ui",
"test:coverage": "vitest run --coverage",
"blueprint": "vite-node scripts/create-blueprint.ts",
"lint": "eslint \"{src,apps,libs,test}/**/*.(ts|vue)\" --fix",
"postinstall": "npm run models:pull",
"models:pull": "node-llama-cpp pull --dir ./resources/models \"hf:bartowski/gemma-2-2b-it-GGUF/gemma-2-2b-it-Q6_K_L.gguf\""
},
"dependencies": {
// ...
},
"devDependencies": {
// ...
}
}接下來新增一個 preload 的 API,用來執行 LLM。
不過在開始前,我們來重構一下目前 preload 的程式碼,讓 electron-env.d.ts 的形別自動推導,不要再手動定義一次。
electron\preload.ts
import type { UserConfig } from './electron-env'
import { contextBridge, ipcRenderer } from 'electron'
export const mainApi = {
updateHeight(height: number) {
return ipcRenderer.send('main:updateHeight', height)
},
hideWindow() {
return ipcRenderer.send('main:hideWindow')
},
openExternal(url: string) {
return ipcRenderer.send('main:openExternal', url)
},
}
contextBridge.exposeInMainWorld('main', mainApi)
export const configApi = {
get() {
return ipcRenderer.invoke('config:get')
},
update(data: Partial<UserConfig>) {
return ipcRenderer.invoke('config:update', data)
},
onUpdate(callback: (config: UserConfig) => void) {
ipcRenderer.on('config:onUpdate', (event, config) => {
callback(config)
})
},
}
contextBridge.exposeInMainWorld('config', configApi)electron-env.d 只要引入 preload 的 API 定義即可。
electron\electron-env.d.ts
import type { configApi, mainApi } from './preload'
export interface UserConfig {
kaomoji: {
databaseId: string;
token: string;
};
}
declare global {
interface Window {
main: typeof mainApi;
config: typeof configApi;
}
}
export { }現在來新增 LLM API。
electron\preload.ts
// ...
export const llmApi = {
prompt(message: string): Promise<string> {
return ipcRenderer.invoke('llm:prompt', message)
},
}
contextBridge.exposeInMainWorld('llm', llmApi)electron\electron-env.d.ts
// ...
declare global {
interface Window {
main: typeof mainApi;
config: typeof configApi;
llm: typeof llmApi;
}
}
export { }接著在 main 中實作 LLM 的 API。
electron\main.ts
// ...
async function initIpcMain(
{
configStore,
}: {
configStore: ConfigStore;
},
) {
// main
ipcMain.on('main:updateHeight', (event, height: number) => {
const window = BrowserWindow.fromWebContents(event.sender)
window?.setBounds({ height })
})
ipcMain.on('main:hideWindow', (event) => {
const window = BrowserWindow.fromWebContents(event.sender)
window?.setFocusable(false)
window?.hide()
})
ipcMain.on('main:openExternal', (event, url: string) => {
shell.openExternal(url)
})
// config
ipcMain.handle('config:get', async () => {
return configStore.get('config')
})
ipcMain.handle('config:update', async (event, config) => {
const data = configStore.get('config')
configStore.set('config', {
...data,
...config,
})
// 向所有視窗觸發 config:onUpdate 事件
BrowserWindow.getAllWindows().forEach((window) => {
window.webContents.send('config:onUpdate', config)
})
})
// llm
/**
* node-llama-cpp 只支援 ESM
*
* 直接 import 會出現 Error [ERR_REQUIRE_ESM]: require() of ES Module 錯誤
*
* https://node-llama-cpp.withcat.ai/guide/troubleshooting#using-in-commonjs
*/
const { getLlama, LlamaChatSession, resolveModelFile } = await import('node-llama-cpp')
const modelPath = await resolveModelFile(
'hf_bartowski_gemma-2-2b-it-Q6_K_L.gguf',
modelsDirectory,
)
const llama = await getLlama()
const model = await llama.loadModel({ modelPath })
const context = await model.createContext()
let session: LlamaChatSession | undefined
ipcMain.handle('llm:prompt', async (event, message: string) => {
if (session) {
session.dispose({ disposeSequence: true })
}
session = new LlamaChatSession({
contextSequence: context.getSequence(),
})
const answer = await session.prompt(message)
session.dispose({ disposeSequence: true })
session = undefined
return answer
})
}
// ...
app.whenReady().then(async () => {
const configStore = createConfigStore()
await initIpcMain({ configStore })
const mainWindow = await createInputWindow()
initGlobalShortcut({ mainWindow })
const tray = createTray({ mainWindow })
app.on('window-all-closed', () => {
if (process.platform !== 'darwin') {
app.quit()
}
globalShortcut.unregisterAll()
tray.destroy()
})
})現在讓我們來試試效果。
src\App.vue
<template>
{{ ans }}
<router-view />
</template>
<script setup lang="ts">
import { ref } from 'vue'
import { useLlmApi } from './composables/use-llm-api'
// ...
const llmApi = useLlmApi()
const ans = ref('')
llmApi.prompt('你好 gemma').then((answer) => {
ans.value = answer
})
</script>
// ...
成功取得 gemma 回應!( ´ ▽ ` )ノ
重構 main.ts
main.ts 的東西越來越多了,現在讓我們重構一下,將範疇明確的程式碼分離。
拆分的檔案結構如下:
.
└── electron/
├── app/
│ ├── config.ts
│ ├── global-shortcut.ts
│ ├── llm.ts
│ └── tray.ts
├── electron-env.d.ts
├── main.ts
└── preload.ts內容就不一一列出了,主要就是將 main.ts 中的程式碼分別放到 app 目錄下的檔案中。
現在 main.ts 變得相當精簡。
electron\main.ts
import type { ConfigStore } from './electron-env'
import process from 'node:process'
import {
app,
BrowserWindow,
globalShortcut,
ipcMain,
shell,
} from 'electron'
import {
createConfigStore,
initConfigIpc,
} from './app/config'
import { initGlobalShortcut } from './app/global-shortcut'
import { initLlmIpc } from './app/llm'
import { createTray } from './app/tray'
async function createInputWindow() {
// ...
}
async function initIpcMain(
{
configStore,
}: {
configStore: ConfigStore;
},
) {
// main
ipcMain.on('main:updateHeight', (event, height: number) => {
const window = BrowserWindow.fromWebContents(event.sender)
window?.setBounds({ height })
})
ipcMain.on('main:hideWindow', (event) => {
const window = BrowserWindow.fromWebContents(event.sender)
window?.setFocusable(false)
window?.hide()
})
ipcMain.on('main:openExternal', (event, url: string) => {
shell.openExternal(url)
})
await Promise.all([
initConfigIpc({ configStore }),
initLlmIpc({ configStore }),
])
}
app.whenReady().then(async () => {
const configStore = createConfigStore()
await initIpcMain({ configStore })
const mainWindow = await createInputWindow()
await initGlobalShortcut({ mainWindow })
const tray = await createTray({ mainWindow })
app.on('window-all-closed', () => {
if (process.platform !== 'darwin') {
app.quit()
}
globalShortcut.unregisterAll()
tray.destroy()
})
})產生 tag 近義詞
現在來對顏文字的 tag 產生近義詞吧。
由於調用 LLM 極度消耗資源,同時希望產生每個 tag 的近義詞後,都立即更新到目前的顏文字列表中。
所以我們需要一個佇列來處理這些非同步任務,這裡使用 p-queue 執行非同步任務,一次只執行一個任務。
src\domains\feature-card-kaomoji\use-kaomoji-data.ts
import type { Ref } from 'vue'
import PQueue from 'p-queue'
import { flatMap, unique } from 'remeda'
import { useLlmApi } from '../../composables/use-llm-api'
export function useKaomojiData(
inputText: Ref<string>,
) {
const llmApi = useLlmApi()
// ...
const tagSynonymMap = shallowRef(new Map<string, string>())
const tagSynonymQueue = new PQueue({
concurrency: 1,
timeout: 1000 * 60 * 5,
})
watch(list, piped(
// 先清空 tagSynonymQueue
tap(() => tagSynonymQueue.clear()),
flatMap((item) => item.tags),
unique(),
forEach((tag) => {
tagSynonymQueue.add(async () => {
const synonym = await llmApi.prompt(
`${tag}的 5 個繁體中文近義詞,5 個英文近義詞,全部合併,逗號分隔,不要任何附加資訊,不要標題,不需解釋`,
)
tagSynonymMap.value.set(tag, synonym)
triggerRef(tagSynonymMap)
})
}),
))
// ...
}接著將 tag 與近義詞內容匹配並放入模糊搜尋中。
src\domains\feature-card-kaomoji\use-kaomoji-data.ts
export function useKaomojiData(
inputText: Ref<string>,
) {
const listWithSynonym = computed(() => pipe(
list.value,
map((item) => {
/** 全部拼在一起即可 */
const synonym = pipe(
item.tags,
map((tag) => tagSynonymMap.value.get(tag) ?? ''),
join(','),
)
return {
...item,
synonym,
}
}),
))
const fuseInstance = new Fuse(listWithSynonym.value, {
keys: ['tags', 'synonym'],
})
watch(listWithSynonym, (value) => {
fuseInstance.setCollection(value)
})
const filteredList = computed(() => {
if (inputText.value === '@') {
return listWithSynonym.value
}
const text = pipe(
inputText.value,
(value) => {
if (value.startsWith('@')) {
return value.slice(1)
}
return value
},
(value) => value.trim(),
)
const result = fuseInstance.search(text)
return pipe(
result,
map(prop('item')),
)
})
// ...
}最後讓我們把有近義詞的項目用個小圖示標註一下。
src\domains\feature-card-kaomoji\index.vue
<template>
<template v-if="visible">
<feature-option
v-if="!isFeature"
// ...
/>
<template v-else>
// ...
<feature-option
v-for="item, i in paginationList"
:key="i"
class="w-full px-4 py-1"
:action="() => copy(item.value)"
>
// ...
<div class="flex items-end">
<q-chip
v-for="tag in item.tags"
:key="tag"
:label="tag"
/>
<q-icon
v-if="item.synonym"
color="gray"
name="task_alt"
size="1rem"
/>
</div>
</feature-option>
// ...
</template>
</template>
</template>
// ...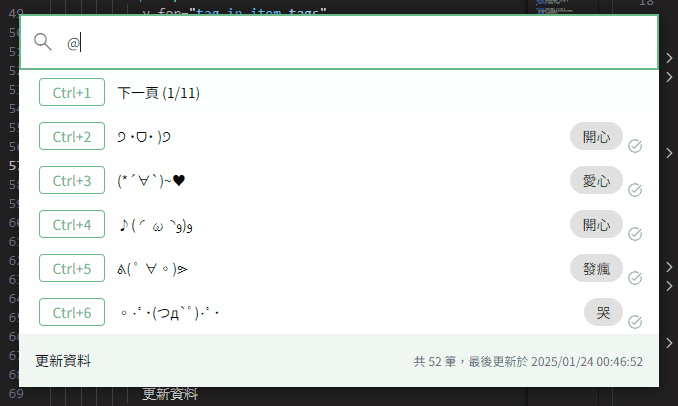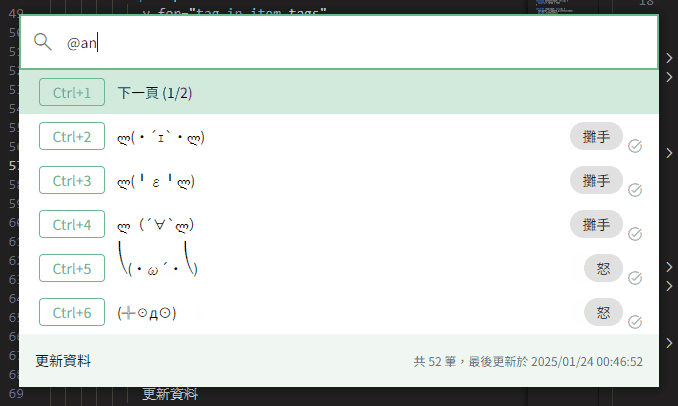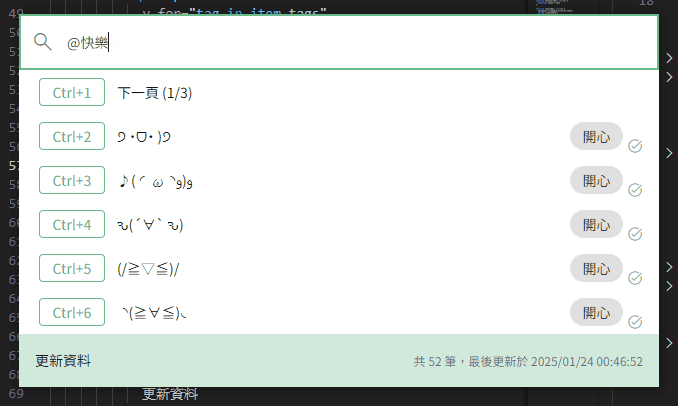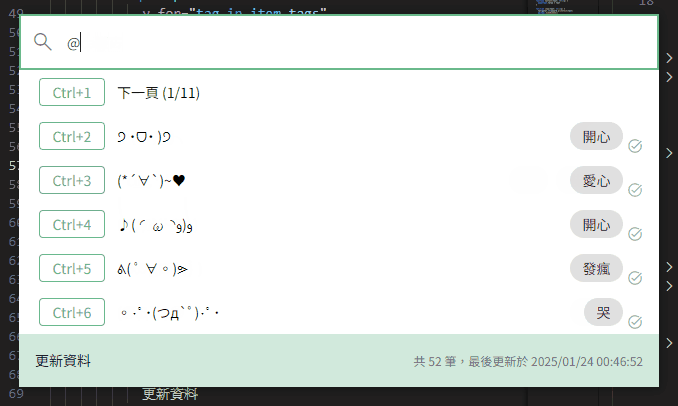
使用體驗提升!✧⁑。٩(ˊᗜˋ*)و✧⁕。
總結 🐟
以上程式碼可以在此取得
我們成功實作了近義詞搜尋,讓使用者可以更快速地找到想要的顏文字。(*´∀`)~♥
模型選用或提詞內容其實還可以持續調整,這個我決定留給未來的自己惹。